文章正文
KILL命令流程全解
这篇文章在我的博客中是在另一篇的基础上完成的,http://www.sbfeng.cn/blog/detail?blogId=1454242937
本文以android6.0.0源码为基础,内核版本3.10,其他代码大同小异。
一、kill之冰山一角
Kill是一个信号发送的程序,可发送的信号包括如下:
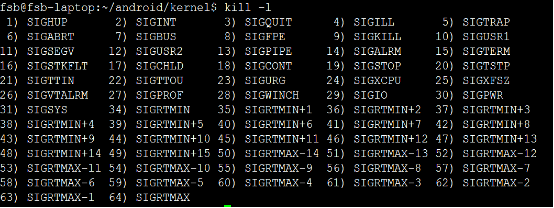
在Android6.0中,代码位置external/toybox/toys/posix/kill.c,这个代码比较简单,最终会调用kill(procpid, signum),也即Kill程序最终通过系统调用kill发送信号。
第二、kill之徐妃半面
在系统调用之后,
SYSCALL_DEFINE2(kill, pid_t, pid, int, sig)
2919 {
2920 struct siginfo info;
2921
2922 info.si_signo = sig;
2923 info.si_errno = 0;
2924 info.si_code = SI_USER;
2925 info.si_pid = task_tgid_vnr(current);
2926 info.si_uid = from_kuid_munged(current_user_ns(), current_uid());
2927
2928 return kill_something_info(sig, &info, pid);
2929 }kill_something_info会调用kill_pid_info,进一步调用group_send_sig_info,将signal信息发送给进程中的所有的线程,group_send_sig_info函数在进一步调用do_send_sig_info, __send_signal等函数将信号挂到对应任务上。发送kill -9的信号终归走到内核中的signal.c文件的complete_signal函数中,通过sigaddset函数将对应进程或线程的pending.signal置为SIGKILL,调用signal_wake_up会将对应进程或线程唤醒 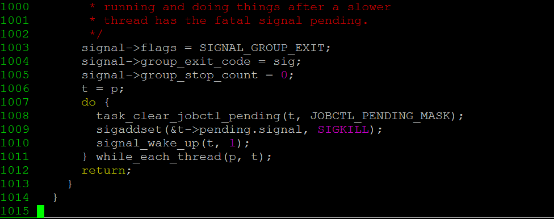
Include/linux/Sched.h
2682 static inline void signal_wake_up(struct task_struct *t, bool resume)
2683 {
2684 signal_wake_up_state(t, resume ? TASK_WAKEKILL : 0);
2685 }Signal_wake_up 的resume参数传入1时,signal_wake_up_state的参数会传入TASK_WAKEKILL,最后在signal_wake_up_state函数中调用kick_process(schd/core.c)函数,发送一个处理器的中断。
第三、kill之深不可测
在kill的进程唤醒之后,会检测到pending.signal置为SIGKILL,这时不会返回用户空间,如果是SIGTERM也就是一般的kill信号,会返回到用户空间注册的处理 函数中。进程中的线程最终会调用到do_exit函数,做最后的退出操作。下面详细分析一下这个函数。
void do_exit(long code)
{
struct task_struct *tsk = current;
struct timespec start;
int group_dead;
profile_task_exit(tsk);
WARN_ON(blk_needs_flush_plug(tsk));
if (unlikely(in_interrupt()))
panic("Aiee, killing interrupt handler!");
if (unlikely(!tsk->pid))
panic("Attempted to kill the idle task!");
set_fs(USER_DS);
set_fs()和get_fs()宏来改变内核对内存地址检查的虚拟地址空间上限,USER_DS表示,可以访问用户空间地址,如果在内核中使用系统调用,必须设置set_fs(KERNEL_DS);将其能访问的空间限制扩大到KERNEL_DS,这样就可以在内核顺利使用系统调用了。在这里使用set_fs(USER_DS),是为了防止后续的mm_release()->clear_child_tid()操作写用户控制的内核地址。
ptrace_event(PTRACE_EVENT_EXIT, code);
validate_creds_for_do_exit(tsk);
/*
* We're taking recursive faults here in do_exit. Safest is to just
* leave this task alone and wait for reboot.
*/
if (unlikely(tsk->flags & PF_EXITING)) {
printk(KERN_ALERT
"Fixing recursive fault but reboot is needed!\n");
/*
* We can do this unlocked here. The futex code uses
* this flag just to verify whether the pi state
* cleanup has been done or not. In the worst case it
* loops once more. We pretend that the cleanup was
* done as there is no way to return. Either the
* OWNER_DIED bit is set by now or we push the blocked
* task into the wait for ever nirwana as well.
*/
tsk->flags |= PF_EXITPIDONE;
set_current_state(TASK_UNINTERRUPTIBLE);
schedule();
}
exit_signals(tsk); /* 设置 PF_EXITING */
设置这个标记表示current task正在退出,可以确保退出的任务可以完全释放互斥的一些锁
smp_mb();
raw_spin_unlock_wait(&tsk->pi_lock);
内存屏障,用于确保在它之后的操作开始执行之前,它之前的操作已经完成
if (unlikely(in_atomic()))
printk(KERN_INFO "note: %s[%d] exited with preempt_count %d\n",
current->comm, task_pid_nr(current),
preempt_count());
acct_update_integrals(tsk);
/* sync mm's RSS info before statistics gathering */
if (tsk->mm)
sync_mm_rss(tsk->mm);
上面的这两个函数会及时的更新分配给进程的页框数(RSS)以及进程地址空间的大小(页数)
group_dead = atomic_dec_and_test(&tsk->signal->live);
group_dead这个变量表示是否是进程中的最后一个线程。
if (group_dead) {
hrtimer_cancel(&tsk->signal->real_timer);
exit_itimers(tsk->signal);
if (tsk->mm)
setmax_mm_hiwater_rss(&tsk->signal->maxrss, tsk->mm);
}
acct_collect(code, group_dead);
if (group_dead)
tty_audit_exit();
audit_free(tsk);
live用来表示线程组中活动线程的数,如果没有其他任务,清除定时器,并做审计记录
tsk->exit_code = code;
taskstats_exit(tsk, group_dead);
exit_mm(tsk);
这个函数是释放内存的函数,最终会调用fork.c里面的mmput释放内存。
if (group_dead)
acct_process();
trace_sched_process_exit(tsk);
exit_sem(tsk);
exit_shm(tsk);
exit_files(tsk);
exit_fs(tsk);
清除任务所涉及的每个IPC信号量的操作痕迹,释放文件对象相关资源以及fs_struct结构体。
if (group_dead)
disassociate_ctty(1);
如果任务全部退出,脱离控制器终端
exit_task_namespaces(tsk);
exit_task_work(tsk);
check_stack_usage();
exit_thread();
触发thread_notify_head链表中所有通知链实例的处理函数,用于处理struct thread_info结构体
/*
* Flush inherited counters to the parent - before the parent
* gets woken up by child-exit notifications.
*
* because of cgroup mode, must be called before cgroup_exit()
*/
perf_event_exit_task(tsk);
性能事件标记的东西退出
cgroup_exit(tsk, 1);
删除cgroup,所有的cgroup操作,包括删除对应的文件节点,都会在这里处理。
module_put(task_thread_info(tsk)->exec_domain->module);
proc_exit_connector(tsk);
ptrace_put_breakpoints(tsk);
退出进程连接器,并删除所有断点信息。
exit_notify(tsk, group_dead);
通知父进程,子进程退出的消息用于更新信息。
#ifdef CONFIG_NUMA
task_lock(tsk);
mpol_put(tsk->mempolicy);
tsk->mempolicy = NULL;
task_unlock(tsk);
#endif
在NUMA中,当引用计数为0时,释放struct mempolicy结构体所占用的内存
#ifdef CONFIG_FUTEX
if (unlikely(current->pi_state_cache))
kfree(current->pi_state_cache);
#endif
/*
* Make sure we are holding no locks:
*/
debug_check_no_locks_held();
检查是否还有未释放的锁资源。
#ifdef CONFIG_ILOCKDEP
if (tsk->ilockdep_lock.depth > 0) {
pr_err("task %s[%d]exit with hold lock:\n",
tsk->comm, tsk->pid);
show_ilockdep_info(tsk);
}
#endif
/*
* We can do this unlocked here. The futex code uses this flag
* just to verify whether the pi state cleanup has been done
* or not. In the worst case it loops once more.
*/
tsk->flags |= PF_EXITPIDONE;
if (tsk->io_context)
exit_io_context(tsk);
if (tsk->splice_pipe)
free_pipe_info(tsk->splice_pipe);
if (tsk->task_frag.page)
put_page(tsk->task_frag.page);
validate_creds_for_do_exit(tsk);
preempt_disable();
if (tsk->nr_dirtied)
__this_cpu_add(dirty_throttle_leaks, tsk->nr_dirtied);
exit_rcu();
smp_mb();
raw_spin_unlock_wait(&tsk->pi_lock);
/* causes final put_task_struct in finish_task_switch(). */
tsk->state = TASK_DEAD;
tsk->flags |= PF_NOFREEZE; /* tell freezer to ignore us */
schedule();
设置TASK_DEAD状态,调度器会忽略这种状态的任务,并且不再冻结。最后调度到其他任务上。
BUG();
/* Avoid "noreturn function does return". */
for (;;)
cpu_relax(); /* For when BUG is null */
}
EXPORT_SYMBOL_GPL(do_exit); 在do_exit退出中,大部分的线程都能很快的退出,在最后一个线程会做最后的清理操作,在进程退出的操作中,也是最后一个线程退出最耗时,在手机上一个app 进程的退出会使用150ms左后,在释放内存以及清理资源上耗时占80%的时间。
参考文献
【1】http://lifeofzjs.com/blog/2015/03/22/what-happens-when-you-kill-a-process/
May 8, 2016, 8:59 a.m. 作者:zachary 分类:Linux相关 阅读(3177) 评论(0)